When discussing IT with the business side of an enterprise the general opinion is that IT departments should, among other things, be like a utility company. Providing services to the business so they can accelerate in what they do. Not dictating how to do business but providing the services needed, when, where and how the business needs them. This point of view is a valid one, and is fueled by the rise of cloud and the Business Driven IT Management paradigm.
The often forgotten, overlooked or deliberately ignored part of viewing your IT department as a utility company is that the consumer is charged based upon consumption. In many enterprise, large and small the funding of the IT department and the funding of projects is done based a perceptual charge of the budget a department receives in the annual budget. The consolidated value of the IT share of all departments is the budget for the IT department. Even though this seems to be reasonable fare way it is in many cases an unfair distribution of IT costs.
When business departments consider the IT department as a service organization in the way they consider utility companies a service organization the natural evolutionary step is that the IT department will invoice the business departments based upon usage. By transforming the financial funding from the IT department from a budget income to a commercial gained income a number of things will be accomplished:
- Fare distribution of IT costs between business departments
- Forcing IT departments to become more effective
- Forcing IT departments to become more innovative
- Forcing IT departments to become more financially aware
One of the foundations of this strategy is that the IT department will be able to track the usage of systems. As companies are moving to cloud based solutions, implementing systems in private clouds and public clouds this is providing the ideal moment in time to go to pay-per-use model.
When using Oracle Enterprise Manager as part of your cloud, as for example used in the blog post “The future of the small cloud” you can also use the “metering and chargeback” options that are part of the cloud foundation of Oracle Enterprise Manager.
Oracle Enterprise Manager allows you to monitor the usages of assets that you define, for a price per time unit you define. When deploying the metering and chargeback solution within Oracle Enterprise Manager the implementation models to calculate the price per time unit for your internal departments are virtually endless.
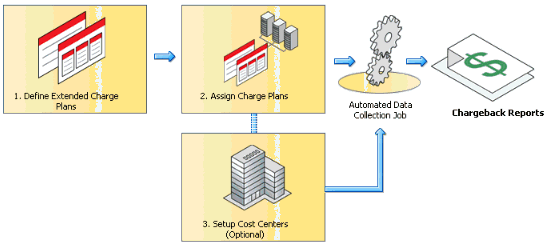
The setup of metering and chargeback focuses around defining charge plans and assigning the charge plans to specific internal customers and cost centers.
The setup of the full end-to-end solution will take time, time to setup the technical side of things as shown as an example screenshot below. However, the majority of the time you will need to spend is to identify and calculate what the exact price for an item should be. This should include all the known costs and hidden costs IT departments have before it is delivered to internal customers. For example, housing, hosting, management, employees, training, licenses, etc etc. This all should be calculated into the price per item per time unit. This is a pure financial calculation that needs to be done.
Even though metering and chargeback is a part of the Oracle Enterprise Manager solution in reality it is in most companies used as a metering and showback solution to inform internal departments about the costs. A next step is for companies currently using metering and showback within Oracle Enterprise Manager is to really bill internal departments based upon consumption. This however is more an internal mind change then a technological implementation.
Implementing “metering and chargeback” is a solution that is needed more and more in modern enterprise. Not purely from a technical point of view but rather more from a business model modernization point of view. By implementing Oracle Enterprise Manager as the central management and monitoring solution and include the “metering and chargeback” options modern enterprises get a huge benefit out of the box and have a direct benefit.