Oracle databases are very commonly used in secured environments and are in many cases considered as a vital part of the IT infrastructure of a company. Oracle databases are often used to provide database solutions to core financial and operational systems. Due to this reason the security of your database and the entire infrastructure design needs to be in the minds of all involved. One of the things however commonly overlooked by application administrators / database administrators and developers is how the infrastructure is done. In many companies the infrastructure is done by another department then the people responsible for the applications and the database.
While it is good that everyone within an enterprise has a role and is dedicated to this it is also a big disadvantage in some cases. The below image is a representation of how many application administrators and DBA's will draw there application landscape (for a simple single database / single application server design).
In essence this is correct however in some cases to much simplified. A network engineer will draw a complete different picture, a UNIX engineer will draw another picture and a storage engineer another. Meaning you will have a couple of images. One thing however where a lot of disciplines will have to work together is security, the below picture is showing the same setup as in the image above however now with some vital parts added to it.
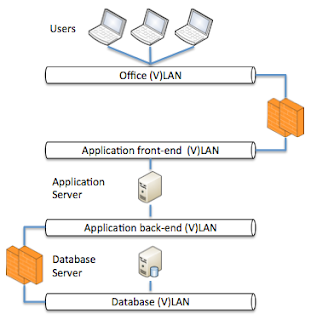
The important part that is added in the above picture is the fact that is shows the different network components like (V)LAN's and firewalls. In this image we excluded routers, switches and such. The reason that this is important is that not understanding the location of firewalls can seriously harm the performance of your application. For many, not network type of people, a firewall is just something you will pass your data through and it should not hinder you in any way. Firewall companies try to make this true however in some cases they do not succeed.
Even though having a firewall between your application server and database server is a good idea, when not configured correctly it can influence the speed of your application dramatically. This is specially the case when you have large sets of data returned by your database.
Reason for this is how a firewall appliance, in our example a Cisco PIX/ASA is handling the SQL traffic and how some default global inspection is implemented in firewalls which are based and do take note of an old SQL*Net implementation of Oracle. By default a Cisco PIX/ASA has implemented some default inspect rules which will do deep packet inspection of all communication that will flow via the firewall. As Oracle by default usage port 1521 the firewall by default has implemented this for all traffic going via port 1521 between the database and a client/applicatio-server.
Reason this is implemented dates back to the SQL*Net V1.x days and is still implemented in may firewalls due to the fact that they want to be compatible with old versions of SQL*Net. Within SQL*Net V1.x you basically had 2 sessions with the database server.
1) Control sessions
2) Data sessions
You would connect with your client to the database n port 1521 and this is referred to as the "control session". As soon as your connection was established a new process would spawn on your server who would handle the requests coming in. This new process received a new port to specifically communicate with you for this particular session. The issue with this was that the firewall in the middle would prevent the new process of communicating with you as this port was not open. For this reason the inspect rules on the firewall would read all the data on the control session and would look for a redirect message telling your client to communicate with the new process on the new port on the database server. As soon as this message was found by the firewall the firewall would open a temporarily port for communication between the database and your client. After that moment all data would flow via the data session.
As you can see in the above image the flow is as follows:
A) Create sessions initiated by the client via the control session
B) Database server creates new process and sends a redirect message for the data session port
C) All data communication go's via the newly opened port on the firewall in the data session
This model works quite OK for a SQL*Net V1.x implementation however in SQL*Net 2.x Oracle has abandoned the implementation of a control session and a data session and has introduced a "direct hand-off" implementation. This means that no new port will be opened and the data sessions and the control session are one. Due to this all the data is flowing via the the control session where your firewall is listing for a redirect that will never come.
The design of the firewall is that all traffic on the control session will be received, placed in a memory buffer, processed by the inspect routine and then forwarded to the client. As the control session is not data intensive the memory buffer is very small and the processors handling the inspect are not very powerful.
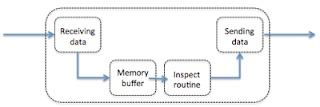
As from SQL*Net V2.x all the data is send over the control sessions and not a specific data session this means that all your data, all your result sets and everything your database can return will be received by your firewall and will be placed in the memory buffer to be inspected. The buffer in general is something around 2K meaning it cannot hold much data and your communication will be slowed down by your firewall. In case you are using SQL*Net V2.x this is completely useless and there is no reason for having this inspect in place in your firewall. Best practice is to disable the inspect in your firewall as it has no use with the newest implementations of SQL*Net and will only slow things down.
You can check on your firewall what is currently turned on and what not as shown in the
example below:
class-map inspection_default
match default-inspection-traffic
policy-map type inspect dns preset_dns_map
parameters
message-length maximum 512
policy-map global_policy
class inspection_default
inspect dns preset_dns_map
inspect ftp
inspect h323 h225
inspect h323 ras
inspect rsh
inspect rtsp
inspect esmtp
inspect sqlnet
inspect skinny
inspect sunrpc
inspect xdmcp
inspect sip
inspect netbios
inspect tftp
service-policy global_policy global








