The personal view on the IT world of Johan Louwers, specially focusing on Oracle technology, Linux and UNIX technology, programming languages and all kinds of nice and cool things happening in the IT world.
When you are using the Oracle VM Manager you will need a database to be used as a repository. You have the option to use an Oracle database or a MySQL database. However, one way or another you will need this to be a part of your overall deployment architecture. As normal when working with databases you do have the tendency to be very careful with this database as it holds all your information. However, what is shown in the below video is that you do not have to be that stressed when your database is lost for some reason.
As you can see from the below image the Oracle VM Manager database is a central connection point where a lot of the information is stored that helps the Oracle VM Manager to operate.
If you have a look at the video below, created by Poor Frodo, you will see that having an accident which results in loosing your Oracle VM Manager database it might not be such a devastating disaster as you might think at first hand. It is still very inconvenient however it will not cripple your operation and you will still be able to manage your VM's. You are even able to restore a lot of the lost information during the reinitialisation process when you install a new repository database.
When we look at the internet and then primarily at the world wide web part of the internet where webpages are offered to users we see there is a good level of interoperability and standards. Webpages are offered primarily on HTML and HTML and HTTP, originally invented by Tim Berners-Lee, are adopted by the majority of services offered online. The protocols lower in the stack like TCP/IP are well defined and clear to everyone and are the foundation that enables communication. when the first steps where taken to create those protocols the number of people involved where not that big and making sure new ideas where adopted where somewhat less troublesome. At this moment more and more people do have access to the internet and do have (some) level of understanding about how to develop new solutions.
When we look at the internet of things we see that a lot of people, organisations and companies are developing solutions that are added to the concept of the internet of things. Most of those solutions do make use of some of the existing standards. for example, most make use of TCP/IP and a large part of them makes use of the HTTP protocol to communicate data. What is missing however is a set of documented standards on what will be communicated and how we can enable interoperability between devices from different vendors.
Qualcomm is trying to make an attempt to start such a standard. Qualcomm developed the alljoyn solution and has now joined the allseen alliance. By doing so they have given over the alljoyn code to the Linux foundation in the hope that this will help fuel the adoption of a unified protocol for the internet of things.
The allseen alliance is currently rapidly growing and is certifying devices that are compliant to the standards of the alliance. members include:LG, Sharp, Haier, Panasonic, Sears Brand Management Corporation, Silicon Image, Cisco, TP-LINK, Canary, doubleTwist, Fon, Harman, HTC, Lifx, Liteon, Sproutling and Wilocit
For years the selection process of ERP systems has primarily been based upon the functionality the ERP system provides. Also the primary party in selecting the ERP system has been the IT department followed by the other departments. However we do see a changing trend. As rightly stated by the Wall Street Journal: "“Functionality is no longer the definition of success. Usability is key". In a recent Forbes article discussing the decision from Avon to stop the implementation of SAP in favor of Oracle JD Edwards it shows that ERP systems selection and implementation is getting more and more influenced by the Apple effect.
The apple effect is the consumerization of IT. Users do expect to have the same experience in the corporate applications as they experience in the consumer applications. This makes that users do expect to have the same kind of ease in using an application and the same user centered approach build into the core of an application and even in the complete portfolio of an IT department. This means that things like user interface design, gamification, agility and self-service solutions become more and more a central part of the corporate solutions and can no longer be seen as an addition or nice-to-have. At the same time users, now digital natives, do expect to be able to work everywhere, always and on every device. Something that is new to corporate IT however something that has to be adopted by IT departments.
Where IT departments where calling the shots previously and where banking on the fact that the user community was not aware about the possibilities this is now changing. With generations coming into the workplace who are used to work with computers and who are digital natives the non-IT departments are getting a stronger voice in the boardroom and are influencing the IT departments. This makes that IT is becoming, as it should, a service organisation to support day to day operations rather then a department that dictates how the business should work.
Combining the consumerization of IT and a business driven IT management strategy is providing IT organisations a stable solution for the future and this should be on the agenda of every CIO. However, as this is a fundamental change in the way IT departments think and operate this is a, clearly necessary however, slow and complex process.
Oracle is already securing its place in the cloud era for some time by providing a number of cloud based solutions as well as software and hardware which enables companies to build private (or hybrid) clouds within their own datacenters. One area however which has not been touched that much by Oracle is the Infrastructure as a Service area.
If you take a close look at the Oracle cloud strategy which has been forming in past couple of years and if you have been looking closely at the products in both hardware and software this should not come as a surprise to many. What you could seen is that Oracle has been working on a lot of solutions that are all part of a cloud / IaaS foundation. In recent years it has become clear that Oracle is using the public market as some sort of testing ground and have the product they put out in the market, end up up in the Oracle cloud solutions. Another giveaway could have been the fact that Oracle has started to embrace OpenStack which was a clear giveaway that IaaS was the way to go in the minds of the Oracle executives.
In the recent second quarter financials call from Oracle given by Larry Ellison the statement made was: "his company intends to be price competitive with established cloud infrastructure-as-a-service players like Amazon, Microsoft and Rackspace". Also stated by Larry was: "We intend to compete aggressively in the commodity infrastructure as a service marketplace". According to Oracle this should start unfolding in the first half year of 2014
This news, even though one could have expected it, will ensure that other IaaS competitors will have to start watching and battling Oracle in this field in which previously Oracle was not a player.
Already for some time virtual assistants are claiming a place in the market. According to Gartner a Virtual assistant is; “a conversational, computer-generated character that simulates a conversation to deliver voice- or text-based information to a user via a Web, kiosk or mobile interface. A VA incorporates natural-language processing, dialogue control, domain knowledge and a visual appearance (such as photos or animation) that changes according to the content and context of the dialogue. The primary interaction methods are text-to-text, text-to-speech, speech-to-text and speech-to-speech”
Digital assistance are playing more and more a role in the way humans interact with systems and the way, for example, customer care processes are shaped. They way people do think about how services should be provide is more and more on an always and everywhere presumption. People do have the need to be able to interact with a company at any moment in time and do expect to be helped directly. Companies who do offer poor quality of service for their customer care and customer support desks will find themselves moving down in the user satisfaction which will result directly to loss in revenue and harm to their brand. A number of options to implement are available; among them is a better way of interacting with the customer via a digital assistant who is present on your website.
Digital assistants have come a long way and due to the maturing of artificial intelligence the usability of digital assistance has grown over the years. By having a digital assistant on your website present you can lower the load on your human Servicedesk and provide customers with a faster way of finding services and answers to their questions online without the need for human interaction. A research paper from Nuance shows that 71% of the consumers prefer a web virtual assistant over a static web experience.
Virtual assistance can play a number of roles on your website all with the goal to enhance the customer experience and at the same time lower the load on your human Servicedesk engineers while at the same time also try to boost business by attracting new customers. This can be done in a number of ways. Traditionally the way of interacting primary with a human representative, more commonly nowadays is that a consumer first is looking at the information presented on the website and if they are unable to locate the correct information or are unable to find answers to their problems they will interact with the Servicedesk, via email or via phone. Depending on the content of your website and depending on the quality of this content and ease of finding you will lower the number of interactions between the Servicedesk and the consumer.
The inability of your customers to locate the information they need is having two negative effects, firs the customer is frustrated because he is not getting the online experience he would like to have, secondly the load to your Servicedesk is increasing due to the fact more customers have a need to interact with you human Servicedesk. Shown in the below diagram you can see the flow (1) customer searching for information on your website, (2) the customer was unable to locate the required information and contacts the Servicedesk and finally (3) the customer is directed by the Servicedesk to the website where the customer can find the correct information.
When you deploy a virtual assistant the changes that there was a need to interact with a human service desk would be much more limited. The digital assistant could take over the role from the human Servicedesk and first try to help the customer by applying artificial intelligence. This would result in the following; the customer visits the website and interacts with the virtual assistant, (2) the virtual assistant directs the customer to the correct location on the website where the information can be found. In case the customer is still not finding the answers he is looking for the digital assistant can establish a connection for the customer with a human Servicedesk representative.
Even though we still keep the option open for customers to interact directly or via the digital assistant with a human Servicedesk the number of requests that need to be handled by the human Servicedesk is, in general, dropping significantly.
Even thought the above method is adding a lot of benefit to the experience of the customer and is limiting the number of calls to the human service center it is considered a passive digital assistant. The reason it is passive is that the customer needs to take the first step to start interacting with the digital assistant. A new and more recent implementation for digital assistants is a more active digital assistant. In this deployment model the digital assistant is trying to start the interaction with the customer even before the customer has opened the website.
A general way of implementing this is related to the analysis of publicly available data which can for example reside on social networks. By analyzing social networks you can identify existing customers who state they have a question, remark, complaint or thought about one of the products or services you provide. Traditionally you would be unaware of this up until the moment the customer initiates the contact with your Servicedesk or with the passive virtual assistant. The same can be applicable for potential new customers, if a person who is not identified as a customer provides on a social network signals that he might be a potential new customer you can identify this and start interacting with this person.
Interaction commonly comes down to replying on the original message from the person on social media and directing this person to the digital assistant. Information that has been collected is already given to the digital assistant to ensure the conversation can be directly on topic. The below video is showing a good example of such an implementation.
When interacting with Oracle support it is quite common that you would like to, or asked to, upload files to the oracle support site. This can be for example be a logfile or the output from a diagnostic script. Generally most people download the files to their workstations and then upload it the the Oracle support site. however, in some cases you would like to be able to directly upload the file from the server to the Oracle support website.
You can now use cURL to upload files to transport.oracle.com. cURL is commonly available on most Linux and UNIX systems. "cURL is a computer software project providing a library and command-line tool for transferring data using various protocols. The cURL project produces two products, libcurl and cURL. It was first released in 1997."
To upload a file to a specific service request you can use the below command to do so:
curl –T –u “” ftps://transport.oracle.com/issue//
It is advised to not include the password in your curl command and you will be promoted for it. For more and detailed information you can refer to MOS document: 1547088.2
When using Oracle Enterprise Manager you have the option to store some information on the target in OEM as target properties. Up to recently I was under the assumption that this was a fixed list of target properties. One of the things I was hoping for was that this list would be expandable so you can add more target properties when needed for a business purpose. For example you might want to have a field to register your business owner, security officer, if a system should be compliant to PCI DSS and other things.
Initially I was unable to find a way and Oracle support reported that this indeed was not an option. However, after Oracle development has reviewed the enhancement request I filed they came up with a solution that is already in place. It turns out you can add additional target property fields however not from the GUI, you can only add them by using emcli.
The command to use to add additional target properties for a target in Oracle Enterprise Manager is to add_target_property. By using this command you can extend the number of fields per target type.
For example, if you wanted to extend all targets of the type "oracle_database" with a new target property to store the name of the system owner you could do so be executing the below command;
IHS Automotive has just released a report stating that the concept of connected cars will represent billions for the automotive industry. A raw estimate is that the automobile data systems will represent approximately 14.5 billion dollar in 2020. As a sidenote IHS researches note that this is only the amount that is directly related to the direct automotive industry however not included in this forecast is the revenue for companies and activities who have a spin off from this data. Inlcuding this it is estimated by IHS that this could run between $16 billion and $80 billion.
IHS expect that the following four categories will be of the most benefit directly for the automotive industry;
Diagnostics
Location
User Experience (UX)/Feature Usage
Advanced Driver Assistance System (ADAS)/Autonomy data
The below graph shows the buildup of data for the automotive industry between the year 2010 and 2020 and it shows a rapid growth that is predicted;
Even though this are impressive numbers it is in no comparison to what the actual revenue could be when we take into account the non-direct automotive revenue. This will not only bring new revenue to already existing companies however it will also fuel new companies to build new solutions and services. Interesting question to ask is however, who is the owner of the data collected. Most likely this will be the car manufacturer as this is somehow to be inserted within a contract with the owner. However, in an ideal world the owner of the car should be the owner of the data and should be able to opt for sharing this data, most likely anonymously, witth the rest of the world.
If the automotive industry could come up with a way that all car data could be shared openly accessible and free this could potentially even more fuel new innovations and could provide a hughe momentum for the adoption of systems like this.
A lot of people working on building private or public clouds will be familiar with OpenStack amd will use it or at least have adopted some of the technological thinking behind OpenStack. Less know might be juju and CEPH. Akash Chandrashekar is working as a solution engineer at Canonical which is the organization behind Ubuntu Linux and he gives a very clear explanation how your can build clouds by using OpenStack, juju and CEPH.
To give some highlevel background before watching the video on the 3 components; OpenStack, juju and CEPH.
OpenStack: OpenStack, a cloud-computing project, aims to provide an infrastructure as a service (IaaS). It is free and open-source software released under the terms of the Apache License. The project is managed by the OpenStack Foundation, a non-profit corporate entity established in September 2012 to promote OpenStack software and its community.
juju: Juju (formerly Ensemble) is a service orchestration management tool developed by Canonical Ltd.. It is an open-source project hosted on Launchpad released under the Affero General Public License (AGPL). Juju concentrates on the notion of service, abstracting the notion of machine or server, and defines relations between those services that are automatically updated when two linked services observe a notable modification. This allows for services to very easily be up and down scaled through the call of a single command. For example, a web service described as a Juju charm that has an established relation with a load balancer can be scaled horizontally with a single juju "add-unit" call, without having to worry about re-configuring the load-balancer to declare the new instances: the charm's event based relations will take care of that.
CEPH: Ceph is a free software storage platform designed to present object, block, and file storage from a single distributed computer cluster. Ceph's main goals are to be completely distributed without a single point of failure, scalable to the exabyte level, and freely-available. The data is replicated, making it fault tolerant.
In case you want to view the slides about the presentation deploying openstack and CEP with Juju at your own speed and comfort please find the slides below as they are shared on slideshare.
Recently someone asked me to help out with some coding parts for a startup they where beginning. Some of the things they needed help with where infrastructure related and some where more in data management and some query modeling and optimization on an already existing datamodel done in a MySQL database.
This gave me some options to start exploring again some things in MySQL which is not my standard database to develop in and use as I am more focusing on Oracle databases. Part of the fun was trying to find out why some queries where not working as expected, main reason for this was that the person who originally designed the datamodel had a love for the VARCHAR datatype.
In the database we do have a table named ovsocial_inst which holds an ID column named inst_m_id. For some reason the original datamodel developer created the column as a VARCHAR even though it is only holding numbers. Now some funny effects do happen when you try to sort.
When you execute the following query:
SELECT
inst_m_id
FROM
ovsocial_inst
ORDER BY
inst_m_id
you will get a result something like:
inst_m_id
1
10
2
3
4
5
6
7
8
9
This is somehow a little strange as long as you do not realize that the values of inst_m_id are treated as text. When you consider it to be text everything makes sense and the query is doing exactly what you ask it to do. However, we do not want it to behave in this manner, we do want it to treat the numbers as numbers even though they are stored in a VARCHAR column. To do so in a sort we can use the following query which converts the VARCHAR into an unsigned.
SELECT
inst_m_id
FROM
ovsocial_inst
ORDER BY
convert(inst_m_id,unsigned) ASC
Now you will get a result as you expect;
inst_m_id
1
2
3
4
5
6
7
8
9
10
Now imagine another scenario. we know that the table ovsocial_inst will be relative small so to assign a new ID to a record we would like to query the table for the max inst_m_id + 1 and we would like to use that value to insert a new record. When you do not consider the fact that the values are written to the table in a VARCHAR manner this process will work until you have 10 records in your table. Reason for this is that if you have 9 records in your table the highest value (the latest in the sort) is 9. This means that the new ID is 10 (9+1). When we hit 10 records something strange will happen. when we hit 10 records the highest value or at least the latest in the sort will be 9. This results in a new ID of 9+1 instead of 10+1.
When your ID field inst_m_id would have been a proper column for holding numbers you would use a query like the one below;
SELECT
(max(inst_m_id)+1) as new_id
FROM
ovsocial_inst
however, the above will give the issue as soon as you hit more then 10 records. To prevent this you will need to construct your query like the one below;
SELECT
max(convert(inst_m_id,unsigned))+1 as new_id
FROM
ovsocial_inst
In this way you will ensure that it keeps working even if you hit the 10 marker.
Big data is playing a major part in the future Oracle strategy for all good reasons and we do see that Oracle is adopting and connecting with big data solutions. Oracle is still one of the major players in the database world and for all good reasons they want to assure a place in the future data market space. To be able to do so they will have to adopt and integrate with big data solutions. Even though some people claim that big data is a hype it is holding some vert valuable points. For example the fact that data is growing in such rapid acceleration that (some) companies have to adopt different and new technologies to handle the amount of data that is available to them.
A major part of the Oracle strategy around big data is focussing on how to funnel big-data into subsets which can be loaded into a data warehouse so it can be analysed. As can be seen from the below example everything is to be funnelled into a data warehouse in this approach and then OBIEE or in-database analytics can be used to analyse this subset of the original acquired data.
Within this strategy a couple of options to implement this are available. For once you can use a full Oracle engineered systems approach as shown in the image below or you could go for a solution in which you design and create parts yourself. In the below image you see how the Oracle Big Data Appliance is used to acquire and organize the data that is collected from a number of sources. From the Oracle Big Data Appliance the pre-processed data is stored within databases inside an Oracle Exadata engineered system. Finally analysts will connect to the Oracle Exalytics machine to make use of their standard Oracle BI tools to query the subsets stored within the Oracle Exadata.
One of the advantages of the above outlined solution is that the systems are designed to work together and the time to create a working solution from a infrastructure perspective is short. Also the systems are designed to provide you with a optimised performance. Also the communication between the components is handled by infiniband, for more information on how to connect exadata and exalytics together with infiniband please do refer to my presentation on this subject on slideshare.
When working with API's and webservices JSON is becoming more and more the standard used for "packaging" data. When you are looking into how API's are sending back data to you it will become evident that JSON is winning over XML.
JavaScript Object Notation, is an open standard format that uses human-readable text to transmit data objects consisting of key:value pairs. It is used primarily to transmit data between a server and web application, as an alternative to XML.
Although originally derived from the JavaScript scripting language, JSON is a language-independent data format, and code for parsing and generating JSON data is readily available in a large variety of programming languages.
The JSON format was originally specified by Douglas Crockford, and is described in RFC 4627 and ECMA-404. The official Internet media type for JSON is application/json. The JSON filename extension is .json.
Issue is that when working with JSON it is very easy to have a small mistake somewhere in your JSON file which will break you entire code or makes your code unresponsive during parsing. If you for example use the json_decode function in PHP and your JSON file is having an issue it will simply return NULL as the value of the variable you used in conjunction with the json_decode function. Some debugging can be done using json_last_error() however a good thing to do first is to check if you JSON file is correct formatted.
Thanks to the guys from arc90 lab you can make use of the JSONLint. JSONLint is an online JSON validator which you can also use under the MIT license and which can be downloaded from github.
When you are operating a business 2 consumer website, or any other form of website for that matter you do want to drive people to your website. When operating a B2C service you do tend to the more consumer based social networks to help you in this approach. In general the believe is that, when you like to spread the word of your service, you need to interact on facebook and twitter. Specially twitter is seen as a driving force and solution to interact with customers and it is generally thought that it would drive visitors to your website.
Below graph is created by Statista and shows what drives traffic to your website.
Not very much surprising is that facebook is a large contributor in driving traffic to your website. What is extreme interesting is that Pinterest is driving a lot of traffic to the publishers websites and that this is a lot more then what is coming from twitter. Issue with the above numbers is that they are not plotted on type of website. Twitter might for example be used much more in B2B and in tech. websites.
Reading the above numbers of how pinterest is driving traffic to websites it is good to understand what the demographic breakdown is of the pinterest user community.
The above demographic data from the pinterest community shows that 80% of the users is female and that the largest age group is 25 - 34. Not surprising is that 50% of the users do have children.
So, what is this meaning. Pinterest is most likely not on the top of your social networks you think you should interact on to drive more customers to your website. However, you should benchmark your target audience to the pinterest community. If you, for example, operate a B2C fashion website which focuses on female clothing you very much should focus on this. If you do want to focus on this there are a number of things you should keep in mind to make this a success.
Have a strategie;
Ensure you have a clear strategy of who you want to engage, how you would like to interact with users on Pinterest. Ensure that you have a clear step by step approach on what you will publish when and how you will ensure that users will start spreading your pictures.
Have a recognizable image style;
When people see an image it would be good if they recognize on the first glimpse that it is coming from your company. It might however not be the best practice to have your logo or you name in full over the image. A identifying style is better and making the images look great / look cool or look funny will make it that people are more willing to re-pin them on their own pinterest boards.
Make sure you can measure;
Having your images on pinterest is nice, however, at some point in time you do want to know if your images and your work is resulting in sales and what the effect is. Ensuring you have the correct techniques in place to capture this and to analyse it will be key of tune your strategy. With good reporting you will be able to find out what is working and what is not and how to change things to get more success.
The overall feeling and initial thoughts when talking about big data is commonly that big data is coming from social media. The most used example of big data is to track what customer think and feel about a company or a product when the write something in social media. This is indeed a very good example and a very usable implementation target for the technical parts that form the basis of handling big data.
However, big data is to be honest much more then social media generated content which can be processed and analyzed. Big data is in general talked about by the four V's. Oracle has identified the 4 V's as Volume, Velocity, Variety and Value while IBM is giving the 4 V's another meaning.
Other sources of big data can be very well the output of the sensors in your factory, sensors in a city, a large number of other sources from within your company or outside of your company. Big data can be the output of devices from the internet of things as described in this blogpost.
Whatever the source of your "big" data the common factors are in most cases that their is a large volume of it, it is coming in a variety of formats and it coming at you fast and continuous. When working with big data the following 3 steps are common;
- Acquire
Their is the need to acquire the data from a number of sources. Within the acquire process their is also the need to store the data. Acquire is not necessarily capturing the data. In the example of sensor data the sensor will capture the data and send it to the acquire process.
- Process
When data is acquired and stored it will need to be processed. In some (most) cases this will be organizing the data so it can be used in analysis however it can also be very well processed for other means then analysis.
- Use
Using the processed data is in many cases analyzing or further analyzing the data that comes out of the process step. However it can also be input for other, non, analytic business processes.
In the below you can see the vision from Oracle on those steps in which they acquire, organize and analyze data.
Even though the above is giving a good example a step is missing from the visual representation. As it is shown now the acquire phase is displayed as stored data in HDFS, NoSQL or an transactional database. What one of the big parts of a good big data strategy should hold is a step before it is stored and that is receiving the data. One of the big parts where a lot of time will have to be dedicated is creating a good technological capture strategy. You will have to have "listeners" to which data producers can talk and who will write the data to the storage.
If you take for example the internet of things you will have a lot of devices that will be sending out data. You will have to have receivers to which those devices talk. As we have stated that that big data is characterized by volume, variety and velocity this means that you will have to build a number of receivers and those receivers should be able to handle a lot of messages and data. This means that your transceivers should be able to, for example, balance the load and work in parallel to be able to cope with the load of all devices that send data to them. Also you will have to ensure that the write speed of the data that the transceivers need to store the data is in line with the supply of data that is send to the transceivers.
As it turns out Vine is currently the fastest growing app in the world. Vine is a app developed by the people behind twitter and it provides you the option to record a video of only a couple of seconds and share this directly on facebook or via twitter. In some sense it can be seen as the Instagram for video content. Previously people had the option to share their daily life via social media primarily via text, added to this are now platforms that enable you to share in the form of pictures you take with your mobile phone. With Vine those options are now expanding to video. Already other social media companies are implementing video capabilities. For example Instagram is adding video capabilities to their app. Instagram, a Facebook company is trying hard to push Vine out of the market as you can also read on this BGR.com arcticle.
A "downside" of this new option however is that analyzing and mining meaning out of a video is much harder compared to doing this from text. Companies are already picking up on implementing systems where they harvest for example twitter messages to find people who talk about their product and brand or who talk about products and services offered also by their company.
One part of the newly upcoming technologies has been looking for a place to fit in. The VCA or Video content Analysis segment of the market has been looking into security and surveillance solutions. Primarily used for analysing surveillance camera feeds. As video content is getting more and more a place in the social media arena the demand for software that can analyse the content of those videos will also grow. This will be a field of expertise where most likely companies who have been working on security VCA solutions can step into the social analytics game.
The major downside of VCA is that it is a resource intensive and currently is still experiencing a high level of faulty outcomes. Far from being mature however this sector of the IT industry could grow to heights as we see the number of video content enablers grow.
When developing an technical deployment architecture for a company it is always good to base your architecture on the best practices. Best practices are offered by a number of sources and when reading the best practices it is good to understand where they are coming from and if there is a "second agenda" in the best practices that is offered.
In general the best best practice is are to be found by independent organizations that provide industry best practices. Next to this a good source of best practices can be the numerous blogs that can be found online. a lot of software vendors do provide best practices and also implementation companies do provide best practices. One thing you have to remember though is that there is always the change that the people from the software vendor and/or an implementation partner do write a best practice without keeping in mind a specific business case.
In real world deployments every additional piece of software and hardware is an additional cost on the budget. This additional cost in the budget should be accompanied with a valid business reason. When someone writes without keeping that in mind, or even with the intention to add additional and costly features to the design, the costs of your deployment architecture might not weigh up to the business benefits and needs.
When reviewing a best practice always try to keep the following things in mind:
- Is the goal used in the best practice in line with my business need
- Is this best practice possibly written with a second agenda
- Is this best practice including higher demands then in my situation
- Is his best practice only focusing on a single vendor solution stack and are the options to include solutions from other vendors.
If you keep the above point in the back of your mind best practices you download from software vendors are very usable.
When Oracle integrated Sun Microsystems a couple of years ago part of the acquired technologies was the ZFS filesystem. ZFS is a combined file system and logical volume manager designed by Sun Microsystems. The features of ZFS include protection against data corruption, support for high storage capacities, efficient data compression, integration of the concepts of filesystem and volume management, snapshots and copy-on-write clones, continuous integrity checking and automatic repair, RAID-Z and native NFSv4 ACLs. The ZFS filesystem is (theoretically) capable of holding a maximum of 16 Exbibytes fo data.
As we can see in the Oracle strategy for storage is that they are building and shipping at this moment a number of storage and backup appliances based on the ZFS technology. At this moment they do ship the ZFS storage appliances ZS3-2, ZS3-4, 7120, 7320 and the 7420 and also Oracle is shipping the Sun ZFS backup Appliance.
A lot of exciting technologies are included in the ZFS storage appliances both on hardware level and software level which can help you get performance gains especially when used in combination with Oracle databases. However, often forgotten is that there is a management suite to manage and monitor you storage appliances.
The strategic product roadmap of Oracle, which is not officially communicated, shows that all management and monitoring solutions for both hardware and software should be integrated within the Oracle Enterprise Manager solution or at least (for now) interact with it. For the ZFS storage appliances a plugin is available to include functionality for managing and monitoring ZFS appliances from Oracle Enterprise Manager. You can download the plugin from the Oracle website.
However, next to the integrated way you have a standalone solution for managing and monitoring your ZFS appliances. This solution is holding the ZFS storage appliance analytics which helps tuning your storage to an optimum. The entire analytics solution is based on the dtrace capabilities, this means that a deep core analysis can be done.
In the above video you can see a bot more about the capabilities of the Analytics that you are able to pull out of a ZFS storage appliance and how they can help you in tuning your storage in a more efficient way.
The common analytics that are provided are:
- CPU: Percent utilization
- Cache: ARC accesses
- Cache: L2ARC I/O bytes
- Cache: L2ARC accesses
- Capacity: Capacity bytes used
- Capacity: Capacity percent used
- Capacity: System pool bytes used
- Capacity: System pool percent used
- Data Movement: Shadow migration bytes
- Data Movement: Shadow migration ops
- Data Movement: Shadow migration requests
- Data Movement: NDMP bytes statistics
- Data Movement: NDMP operations statistics
- Data Movement: Replication bytes
- Data Movement: Replication operations
- Disk: Disks
- Disk: I/O bytes
- Disk: I/O operations
- Network: Device bytes
- Network: Interface bytes
- Protocol: SMB operations
- Protocol: Fibre Channel bytes
- Protocol: Fibre Channel operations
- Protocol: FTP bytes
- Protocol: HTTP/WebDAV requests
- Protocol: iSCSI bytes
- Protocol: iSCSI operations
- Protocol: NFSv bytes
- Protocol: NFSv operations
- Protocol: SFTP bytes
- Protocol: SRP bytes
- Protocol: SRP operations
Next to the common analytics there are also a number of things where you can get more detailed and more advanced analytics on;
- CPU: CPUs
- CPU: Kernel spins
- Cache: ARC adaptive parameter
- Cache: ARC evicted bytes
- Cache: ARC size
- Cache: ARC target size
- Cache: DNLC accesses
- Cache: DNLC entries
- Cache: L2ARC errors
- Cache: L2ARC size
- Data Movement: NDMP bytes transferred to/from disk
- Data Movement: NDMP bytes transferred to/from tape
- Data Movement: NDMP file system operations
- Data Movement: NDMP jobs
- Data Movement: Replication latencies
- Disk: Percent utilization
- Disk: ZFS DMU operations
- Disk: ZFS logical I/O bytes
- Disk: ZFS logical I/O operations
- Memory: Dynamic memory usage
- Memory: Kernel memory
- Memory: Kernel memory in use
- Memory: Kernel memory lost to fragmentation
- Network: IP bytes
- Network: IP packets
- Network: TCP bytes
- Network: TCP packets
- System: NSCD backend requests
- System: NSCD operations
Getting all those analytics can be done via the GUI that is provided by Oracle. The mentioned analytics can help you tune your appliance and the way applications are interacting with it. One thing however is of vital importance, that you have a deep understanding of what the figures mean. A good starting guide is analytics guide from Oracle. However, this alone will not be sufficient. When running a mission critical system which is based upon a ZFS storage appliance and you have to deliver the most optimum performance a deep knowledge of ZFS and storage solutions will be needed.
When using a cloud service less and less people are thinking about how things work "under the cloud". The cloud is taken as a given fact without thinking about how a cloud vendor is ensuring everything is working and is capable of providing the scalability and flexibility that comes with a true cloud solution. There is also no need to think about this in many cases, unless you are the one who is building the cloud solution and/or responsible for maintaining the solution.
As already stated by Pat Gelsinger, the VMWare CEO we are entering the third wave of IT which is the Mobile-cloud wave. This third wave is making life much more simpler for a number of people, when you need an environment you can simply request one by your infrastructure-as-a-service provide and most hints will be arranged. When you for example request a new instance at Amazon web services you can simply click your network components together and magically everything is working.
The more complicated factor that is coming in to play which was not (that much) the case in the client-server era is that more and more components need to be virtualised and should be able to be controlled from a central software based portal. This is when SDDC is coming into play, SDDC stands for Software-Defined Data Center and is an architecture approach in which the entire IT infrastructure extending on the virtualisation concept. Within this concept all infrastructure components are delivered as it where software components. In general the main 3 components of a SDDC architecture are:
Compute virtualisation, which is a software implementation of a computer.
Network and security virtualization. Network virtualization, sometimes referred to as software-defined networking, is the process of merging hardware and software resources and networking functionality into a software-based virtual network.The network and security virtualization layer untethers the software-defined data center from the underlying physical network and firewall architecture
Software-defined storage, or storage virtualization, enables data center administrators to manage multiple storage types and brands from a single software interface. High availability, which is unbundled from the actual storage hardware, allows for the addition of any storage arrays as needed.
When we take a look at the Oracle portfolio we do see a tendency towards software-defined-datacenter solutions. As Oracle is adopting the cloud thinking and is not only providing a cloud platform but also is providing the building blocks for customers to build there own (internal) clouds it is not more then logical that we find SDDC supporting solutions.
Oracle Compute virtualisation;
it is without any doubt that Oracle is working on a number of virtualisation technologies where Oracle VM is the most noteworthy and used. Next to this Oracle is working on a Solaris containers approach however for the x86 platforms the common standard is becoming Oracle VM which is based on the XEN hypervisor.
Software defined networking;
In this field Oracle is taking some great steps. Oracle SDN (software defined Network) has been launched some time ago. Oracle SDN boosts application performance and management flexibility by dynamically connecting virtual machines (VMs) and servers to any resource in your data center fabric. Oracle SDN redefines server connectivity by employing the basic concepts of virtualisation. Unlike legacy port- and switch-based networking, which defines connectivity via complex LAN configurations, Oracle SDN defines connectivity entirely in software, using a supremely elegant resource: the private virtual interconnect. A private virtual interconnect is a software defined link between two resources. It enables you to connect any virtual machine or server to any other resource including virtual machines, virtual appliances, bare metal servers, networks, and storage devices anywhere in the data center.
The SDN solution from oracle provides a great set of management and monitoring tools which enables administrators and architects to manage the virtual network in a more efficient way and also tie this into a flexible cloud solution which is architected front he ground up and is fully automated.
Software defined storage;
within the field of software defined storage Oracle is, at this moment, not providing a clear path to the future. However when searching the Oracle website you can find some reports that are hinting or talking about the subject.
There is an IDC report on the oracle website where IDC is stating the following question without answering it directly; "Will Oracle leverage ZFS or ZFS/OpenStack for a software-only, software-defined storage solution for hyperscale cloud builders? Given that Oracle does not have a material storage hardware business to protect and it has an excellent software stack with ZFS (and more enhancements coming), Oracle could really become a strategic supplier to next-generation cloud builders."
I my opinion this is a bit off the mark as Oracle has a storage hardware department where they do build and sell storage appliances however it is true that this is not the main focus of the company however can become a more and more valuable part of the company in the upcoming time.
Next to this there is a report from Dragon Slayer Consulting which can be found on the Oracle website which is also talking for a bit about software defined storage and is also stating some hints on how ZFS appliances can be used in combination with Oracle Enterprise Manager to be used in a software defined storage solution.
Even though there are a lot of options to "trick" components to act like software defined storage solutions and a lot can be done by using Oracle Enterprise Manager there is not a real good definition and a clear path coming from Oracle on what role they will play with regards to Software Defined Storage in the future.
Oracle Enterprise Manager;
We do see a trend that Oracle is integrating the monitoring and management options into Oracle Enterprise Manager and making this the central location for all management tasks. Also Oracle announced that it will be integrating with openstack and will provide OpenStack Swift API's. Having the Oracle Enterprise Manager capabilities extended with OpenStack API's and making more and more components "software defined" Oracle is building a portfolio that is able to form the basis for a full Oracle Red Stack private cloud solution, not only for "small" enterprises but also for large cloud vendors who are willing to provide large scale cloud solutions to large number of (internal or external) customers.
In many companies who do use Oracle products Oracle Enterprise Manager is used for managing and monitoring purposes. This is making Oracle Enterprise Manager more and more a central application used to connect to a number of systems. From some point of view this is a good thing, from other points of view this might be a less favorable thing to do. Primarily from a security point of view a number of security specialists have reasoned that if someone would be able to hack Oracle Enterprise Manager it would be an ideal stepping stone into the rest of the network from the company which is under attack.
Oracle has introduced the option to now use a public/private key pare solution when connecting from Oracle Enterprise Manager to other systems. This is still not satisfying some security officers however it is tying more into the general ssh-key authentication mechanisms used for authentication at UNIX machines used in many companies. The ssh-keys are stored within Oracle Enterprise Manager as part of a named credential. A Named Credential specifies a users' authentication information on a system. Named credentials can be a username/password pair like the operating system login credentials, or Oracle home owner credentials primarily used for performing operations such as running jobs, patching and other system management tasks.
The advantaged of using a SSH key method for login to remote servers using SSH is that this is considered much more secure then using a username/password combination.Public key authentication is one of the most secure methods to authenticate using Secure Shell. Public key authentication uses a pair of computer generated keys - one public and one private. Each key is usually between 1024 and 2048 bits in length, it is useless unless you have the corresponding private key
A guide on how to use SSH keys in OEM can be seen in the below video from Oracle:
It is beyond any doubt that the cloud way of things is picking up, more and more companies to tend to look at cloud solutions in one way or another. Some might even use cloud based solutions without even knowing it and in some cases enterprises are not aware that departments are using cloud based solutions on their own account. This last part is, or at least should, be a concern for the security department. You can better channel the use of cloud solutions then staying unaware of it or block it and find out that users find other ways of still doing it however in slightly different way.
What is interesting is to see how cloud is used and by what kind of companies. How they adopt the cloud way of thinking. Cloud is a given and it is not going away anytime soon. Now we can see how this is unraveling and is adopted in the daily way of doing things within companies.
A good source for such information is the survey from RightScale; " RightScale surveyed technical professionals across a broad cross-section of organisations about their adoption of cloud computing." one things however we have to keep in mind when reading those figures is that the list of people who have been send this survey are (A) technically knowledgeable and (B) most likely in some form a connection with RightScale and might be more cloud orientated then the average business user. Keeping this in mind the report is still providing a good point of view on the current adoption level.
One of the interesting things is that they show the adoption in a four level way between enterprises and small and medium businesses. For this they use the levels "POC/Experiment", "First project", "several apps" and Heavy use. This is used to show the cloud adoption within enterprises and SMB companies. What you can see from this is that the SMB market is already making much more use of cloud then the enterprises, 41% SMB usages of cloud against 17% in the enterprise section of the market.
The levels used for the adoption are somewhat comparable with the cloud adoption model as shown below in a pyramid way of representing this. Int his model we use 5 levels instead of 4. Rightscale is not taking into account the virtualization layer which is represented as level 1 in the below pyramid. For the rest you could see "POC/Experiment" as level 2 Cloud Experimentation, "First Project" as level 3 Cloud Foundations, "Several Apps" as level 4 Cloud Exploitation and "Heavy Use" as level 5 Hyper cloud.
As we have seen form the above information the SMB market is more willing to adopt cloud computing in a "heavy" was and the majority of the SMB companies who use cloud computing do this in a level 5 Hyper cloud way. What is interesting however is that, based upon the RightScale 2013 report, there is not much relative difference between the number of enterprises and SMB companies who use cloud. 75% of all companies do make use of cloud computing, this breaks down in 77% of the enterprises and 73% of the small and medium businesses.
This would hold that the percent of enterprises using the cloud is higher however that they less advanced in the level of adoption of the cloud computing platform. Small and medium business are lacking behind a little however when they start adopting the cloud they tend to go in much more aggressive and move very quickly into a higher rate of adoption.
One of the reasons for this could potentially be that cloud computing is picking up at the moment and needs to find its place. We are still in the "client server" area of computing and where enterprises tend to move slower and have in general more and complex systems then small and medium businesses it takes longer to move to the "cloud and mobile" area. Next to this small and medium businesses tend to have a less complex chain of command and decisions can be made more quicker and without the sometimes complex bureaucracy of large enterprises.
This means, small and medium businesses are more agile and can move quicker into new technologies then enterprises. An additional complexity for adoption is that the amount of money involved for an enterprise is in general much higher then that for a SMB company due to the scale and complexity of the applications used.
What we however see is that large enterprises are very much willing to adopt cloud computing however it takes longer to implement this solution. However, the market for enterprise cloud computing is opening and should be a focus point for all companies who do sell cloud solutions in one form or another.
To protect the database from attempts to hack it in a number of ways commonly a network firewall is implemented to ensure attackers cannot connect to the system running the database on ports other then intended and not from computers that should not be able to connect to the database. This way, as is the traditional and common way, is protecting the database in quite a good fashion however is not protecting it against all risks. If a server who is eligible to connect to the database is compromised an attacker could use this as a stepping stone to execute queries against the database or cause other havoc.
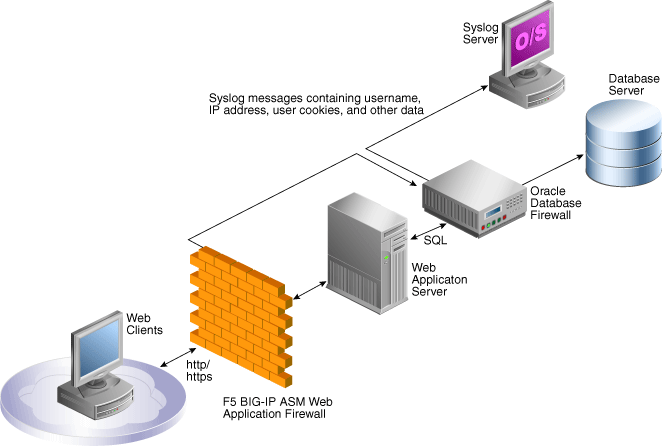
For this reason Oracle has created the the Oracle database firewall. When you deploy and Oracle database firewall your application server is no longer talking directly to your database however to the firewall. Based upon a whitelist or blacklist principle certain statements are allowed to be send to the database. Statements that are not allowed are dropped. having such a solution in place is adding an extra layer of security to your design. An diagram showing such an implementation is shown below.
A less known fact about the Oracle database firewall is however that it can be integrated with other security products from other vendors. F5 for example is providing a solution with the BIG-IP ASM (Application Security Manager) which is is an application layer firewall specially designed to recognise attacks on an application layer level. In most common attacks for systems where you would deploy an Oracle database firewall you will have an application layer which might only be protected by a network firewall. In a solution where you also deploy a application layer firewall you will gain an extra level of security.
The BIG-IP ASM solution is able to detect and block an attack on the application layer and next to this forward this information also to the Oracle database firewall. This has a number of advantages. First of all the attack context is communicated with the Oracle database firewall together with information about the source-IP from the attacker and other information. Based upon the attack context the Oracle database firewall can be tightened in general and/or also on the specific IP from the attacker.
An additional benefit, which is in my opinion a huge benefit, is that you will be able to collect the information and logs of both the F5 firewall and the Oracle database firewall in a consolidated way. In many cases a security apartment needs to track down what happened and needs to be able to report on this and should have a trail of evidence. When multiple points of security and a multiple number of locations for logs are in place it can be very hard to track down the entire attack path and provide a consistent and correct report. Having the ability to do this from a single console is providing much more options to track and secure your vital and confidential data. When looking into securing a Oracle based solution is well worth to think about an implementation as shown above.
Most common users and most developers who every now and then develop an application will not be using Dtrace. however, people involved in building and debugging applications that run under Linux or Solaris and people who are responsible for tuning and optimizing performance of mission critical systems will most likely be using Dtrace or at least they should start understanding it and possibly start using it. Dtrace is a dynamic tracing framework developed by Sun Microsystems for troubleshooting kernel and application issues in real time.
Dtrace gives you the option to truley see what your application is doing and how your operating system kernel is handling stuff. A real view of what is happening can be very good when you are diving deep into debugging applications and issues with your servers.
In the past Dtrace has primarily be used for "server" based applications and not si much for scripting languages. A not well know fact is that Dtrace is also a part of the PHP language. David Soria Parra has merged the Dtrace functions into PHP from PHP version 5.4 and onwards. The original way of using PECL to incorporate Dtrace into PHP.
If you are serious about building PHP applications and serious about finding bottlenecks in your code and the way your PHP code is interacting with your kernel you should look into Dtrace for PHP. Chritoper Jones wrote an article back in 2012 named "Adding DTrace Probes to PHP extensions" and recently wrote an article named "DTrace with PHP update" which are both good starting points. You can find both on the Oracle website in the PHP and Oracle blog from Christopher Jones.