PHP's creator offers his thoughts on the PHP phenomenon, what has shaped and motivated the language, and where the PHP movement is heading
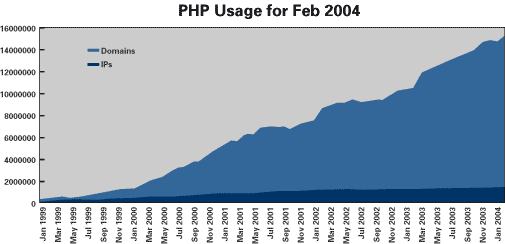
PHP is everywhere. In its February 2004 Web server survey, Netcraft poked 47,173,415 domains and found that 15,205,474 had PHP installed. That is approximately 32 percent of all domains on the Web, and there is no sign of its slowing down.
 The Early Days of PHP
The Early Days of PHPI started developing PHP nearly 10 years ago now. That was long before the term "Open Source" was coined and before the GPL and Free Software was well known. And as with many open source projects that have gone on to become popular, the motivation was never philosophical or even narcissistic. It was purely a case of needing a tool to solve real-world Web-related problems. In 1994 the options were fairly limited when it came to Web development tools. I found myself writing dynamic components for Web sites in C or Perl, and the code overlap from one problem to the next was quite significant. For performance reasons, I was increasingly tending away from Perl and toward C, because the fork+exec overhead of having to run Perl as a standalone CGI was too restrictive.
The initial unreleased version of PHP was mostly a C library of common C functions I had written to be easily reusable from one open source project to the next. I had a simple state-machine-driven parser that picked tags out of HTML files and called the back-end C functions I had written. This code was initially released to the public as a package called Personal Home Page Tools, and each tool in the package was an example of how to use the system to solve a common problem on a personal home page. At some point along the way, I split out a piece and called it FI, for Form Interpreter. The idea behind FI was that it could do all the common things you needed to do when you received the result of a form submit. Some early examples:
[01] <!--getenv HTTP_USER_AGENT-->
[02] <!--ifsubstr $exec_result Mozilla-->
[03] Hey, you are using Netscape!<p>
[04] <!--endif-->
[05]
[06] <!--sql database select * from table where user='$username'-->
[07]
[08] <!--ifless $numentries 1-->
[09] Sorry, that record does not exist<p>
[10] <!--endif exit-->
[11]
[12] Welcome <!--$user-->!
[13] You have <!--$index:0--> credits left in your account.<p>
[14]
[15] <!--include /text/footer.html-->
My parser for FI was terrible, which prompted me to try to write a better one. I moved away from the syntax and went to instead, recombined parts of the Personal Home Page Tools with this new FI tool, and released that as a package called PHP/FI (the name was a bit of a tongue-in-cheek play on TCP/IP) in late 1995. PHP/FI grew right along with the Web over the next couple of years. In 1997 two guys in Israel, Zeev Suraski and Andi Gutmans, who were using PHP/FI asked if I would be interested in using a new parsing engine that they would write for the next version of PHP. I gathered up a few other people who had been sending patches and code for PHP/FI and we all coordinated to release PHP version 3 in mid-1998. This was probably the most crucial moment during the development of PHP. The project would have died at that point if it had remained a one-man effort and it could easily have died if the newly assembled group of strangers could figure out how to work together towards a common goal. We somehow managed to juggle our egos and other personal events and the project grew. The number of contributors has grown steadily and today we are pushing towards a release of PHP 5.0 sometime in the first half of 2004.
The Ugly Duckling of Programming Languages
Popular opinion about PHP is polarized. Language purists tend not to like the somewhat haphazard implementation of many features and some of the inconsistencies that have emerged over the years. At the same time, pragmatic problem solvers tend to love how PHP seems to almost read your mind and present itself as the perfect Web problem solving tool.
Among the things that drive the purists crazy are that names of functions are not case-sensitive but variables are; built-in functions are not consistently named; and no real structure is enforced on PHP developers, making it easy to write messy code. I can't really argue with these criticisms, but I can at least attempt to explain how and why we got to this state.
First, regarding the function-name case-sensitivity issue: This goes back to the very first version of PHP. In the early days of the Web, long before XHTML, it was very common for all HTML markup tags to be uppercase. But because these tags were not case-sensitive, people weren't very consistent about this. I wanted people to treat the special PHP tags as being basically just like other markup tags, which meant that PHP's tags should also not be case-sensitive. As PHP became more advanced and received features such as variables, it didn't hurt to make these new features case-sensitive, because it didn't break backward compatibility with existing PHP pages. Going back and suddenly making the initial simple tags, which were in essence just function calls, case-sensitive would have broken those pages and made them unusable in newer versions of PHP. People shouldn't have functions whose names differ only in case, anyway. Still, in retrospect, it would have been a good idea to break backward compatibility early on, when relatively few people were using PHP, but at the time, nobody could have predicted the amazing growth of PHP.
As to function naming itself, I tended to steal/borrow ideas from other languages and APIs I was familiar with. This means that PHP has functions such as strlen( and substr(), which would look silly if written as str_len() or sub_str(). I added things like stripslashes(), which, because of the length, is often written as StripSlashes() to make it easier to read. At the same time, I mimicked low-level database APIs, with functions such as msql_connect()—miniSQL was the first database to be supported by PHP—which used underscore naming. People familiar with these various sources were quite at home with the naming in PHP. PHP was never so much a standalone language as it was an interface between the Web server and all the various back-end tools you wanted to hook into the Web server. Consequently, when people look at PHP today as a standalone language without taking its context into account, it can appear somewhat inconsistent.
About the lack of enforced structure, all I can say is that I absolutely hate programming frameworks that lock me into a certain way of approaching a problem. That doesn't mean I don't believe in structure and frameworks, but I do believe in people having the power to come up with their own to match their environment. More on this later in the article, when I discuss possible architectures for your various PHP projects.
What it all boils down to is that PHP was never meant to win any beauty contests. It wasn't designed to introduce any new revolutionary programming paradigms. It was designed to solve a single problem: the Web problem. That problem can get quite ugly, and sometimes you need an ugly tool to solve your ugly problem. Although a pretty tool may, in fact, be able to solve the problem as well, chances are that an ugly PHP solution can be implemented much quicker and with many fewer resources. That generally sums up PHP's stubborn function-over-form approach throughout the years.
Advice for Architects
The most popular deployment model for PHP is for it to be linked directly into the preforking multiprocess Apache 1.3.x Web server. Unlike with Java, there is no standalone process like the JVM. PHP is similar to scripting languages such as Perl and Python in that it parses and executes scripts directly.
The lack of a central control process is a feature and at the same time a source of great frustration for many. The shared-nothing architecture of PHP where each request is completely distinct and separate from any other request leads to infinite horizontal scalability in the language itself. PHP encourages you to push scalability issues to the layers that require it. If you need a shared datastore, use a database that supports replication and can scale to the levels you need. If you need to load balance requests or distribute certain requests to certain servers, use a front end load balancer that supports this. By avoiding a central controlling process, PHP avoids being the bottleneck in the system. This is the defining characteristic that separates PHP from what people commonly refer to as application servers.

In the diagram above, one or more load balancers distribute incoming requests across any number of Web servers. For data storage, you might deploy a read-only database replica on each Web server if your dataset is small enough to let you do that, or you might create a separate tree of database servers to handle various types of requests.
Adding Structure
One of the big strengths of PHP over many other tools aimed at solving the Web problem is that other tools tend to associate such very specific targeted problem solving with the need to control how users approach the problem structurally. PHP doesn't impose any such structure, choosing instead to focus on making each individual functionality aspect of the problem as easy as possible to use. For example, PHP provides very targeted functions for communicating with a back-end database. These are specific to each database and do not sacrifice any performance to gain uniformity or consistency with other back-end databases. There is also no set way to structure a PHP application in terms of file layout and what goes where.
The fact that PHP doesn't impose structure doesn't mean that you shouldn't build your PHP applications in an organized and structured way. Here is one approach I like to show people who ask me how I would go about structuring a large PHP application.
+--------------------------------+
| HTML TEMPLATES |
| $DOC_ROOT/*.php |
+--------------------------------+
| TEMPLATE HELPERS |
| $DOC_ROOT/*.inc |
+--------------------------------+
| BUSINESS LOGIC |
| /usr/local/php/*.inc |
+--------------------------------+
| C/C++ CORE CODE |
| /usr/local/lib/php/*.so |
+--------------------------------+
This four-layer approach addresses a couple of issues. First, it separates the content along the lines of responsibility in a typical project. The Web front-end developers work from the top, and the back-end engineers work from the bottom. They overlap a bit in the template helpers layer. It also separates anything that contains HTML, by putting those files into the document_root and anything that doesn't contain HTML outside the document_root.
The top template layer typically contains very little PHP—just simple function calls and the odd include. Perhaps a loop. These files are usually edited with an HTML authoring tool. The second layer, the template helpers, is where the interface between the business logic and the layout is defined. This layer might have convenience functions such as start_table(), show_user_record(), and any other reusable component that makes template authors' lives easier.
The business-logic layer does not contain any HTML at all. This is where such things as SQL queries and any other PHP user-space business logic is implemented. You might expect to see a function such as get_user_record() implemented in this layer. This function would take an ID, perform the appropriate SQL query, and then return an associative array with the result. A function in the layer above then takes this array and wraps some HTML around it to make it look nice.
The final C/C++ layer is where you put any custom back-end code required for a project. Many people will not have anything for this layer, but if you have a proprietary C or C++ library, you can write a PHP extension to interface to that here. Sometimes this layer is also used when a business-logic function written in user-space PHP turns out to be too slow.
Hiring and Training PHP Developers
PHP is not a new language. It doesn't introduce any new concepts. This means that training programmers who already know any C, C++, Perl, or even Java to write PHP code is quite easy. I tend to look for people with C or C++ skills when I go looking for PHP developers for a project, the thinking being that you are much better off hiring experienced programmers than you would be if you hired someone who necessarily knows a lot about PHP. If they can handle those languages, PHP will be trivial for them. Of course, if they have experience with both, so much the better.
Deploying PHP Everywhere
Use the right tool for the job. I have run across companies that have completely bought into PHP, deploying it absolutely everywhere, but it was never meant to be a general-purpose language appropriate for every problem. It is most at home as the front-end scripting language for the Web. Depending on the traffic the Web site gets, it can be used to do the bulk of the back-end work as well. But at a certain point, you are going to need to write part of your code in a strongly typed, compiled language such as C or C++ for optimal performance.
Where Is PHP Going?
People are always asking me what lies ahead for PHP. That is a very difficult question to answer, because PHP is mostly a reactive open source project, in that it evolves to meet the needs of its community. In PHP5, the OO capabilities and integration with XML have been improved greatly. We have integrated an interesting tool called SQL-Lite, which provides a SQL interface directly to a file without requiring a server. It is not a replacement for a real database, obviously, but using it is certainly a much better approach than trying to write your own flat-file manipulation routines. And the fact that it gives you a SQL interface means that migration to a real database becomes easier if that is ever required.
These changes in PHP5, although significant, are evolutionary. We are not turning the world of PHP upside down with this release. Of the scripts written for PHP4, 99 percent will work unchanged in PHP5. The biggest change is that objects are handled differently in PHP5. When you new an object in PHP5, you now, by default, get a reference to that object that you can pass around without explicitly stating that you want the object passed by reference, as you had to in PHP4. If you actually want a copy of the object in PHP5, you need to "clone" it.
Longer-term, there are people exploring the use of the Parrot engine. Parrot was written as the engine behind Perl6, but it is really a language-neutral general-purpose scripting engine. It would be very interesting if the various scripting languages could all agree on a single back-end engine, which could then be used as a basis for common extensions and much better language interaction.
And still others are exploring Java connectivity through JSR 223, with some thinking that Java can be the single universal back end for scripting languages.
Despite what the future may hold for PHP, one thing will remain constant. We will continue to fight the complexity to which so many people seem to be addicted. The most complex solution is rarely the right one. Our single-minded direct approach to solving the Web problem is what has set PHP apart from the start, and while other solutions around us seem to get bigger and more complex, we are striving to simplify and streamline PHP and its approach to solving the Web problem.
Rasmus Lerdorf (rasmus@lerdorf.com) was born in Godhavn/Qeqertarsuaq on Disko Island off the coast of Greenland in 1968. He has been dabbling with UNIX-based solutions since 1985. Known for having gotten the PHP project off the ground in 1995, the mod_info Apache module and he can be blamed for the ANSI92 SQL-defying LIMIT clause in mSQL 1.x which has now, at least conceptually, crept into both MySQL and PostgreSQL.
He tends to deny being a programmer, preferring to be seen as a techy adept at solving problems. If the solution requires a bit of coding and he can't trick somebody else into writing the code, he will (very) reluctantly give in and write it. He is currently an infrastructure engineer at Yahoo! Inc. in Sunnyvale, California.
No comments:
Post a Comment